Next: A ortogonale Up: Risoluzione di sistemi lineari Previous: Risoluzione di sistemi lineari Indice
Se la matrice ![]() è una matrice diagonale, allora assume la forma
è una matrice diagonale, allora assume la forma
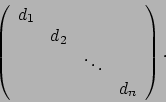
Il determinante di una matrice siffatta è dato dal prodotto degli
elementi diagonali
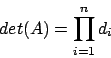
La struttura a diagonale facilita molto il calcolo del vettore
![]() , perché equivale ad avere
, perché equivale ad avere ![]() equazioni disaccoppiate, infatti
equazioni disaccoppiate, infatti
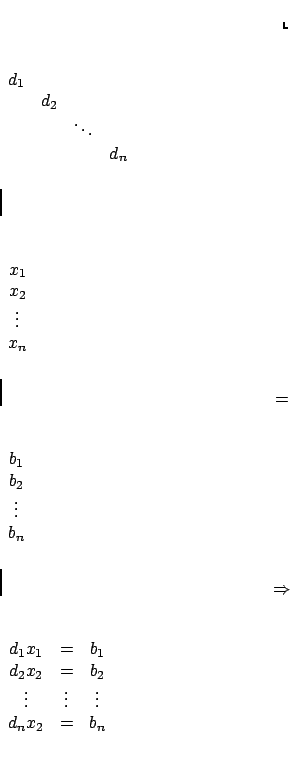

Invece di un problema di dimensione ![]() , abbiamo risolto
, abbiamo risolto ![]() problemi di dimensione
problemi di dimensione ![]() , e quindi impieghiamo
, e quindi impieghiamo ![]() flops.
flops.
Anche l'occupazione di memoria risulta lineare: non è necessario
utilizzare una matrice 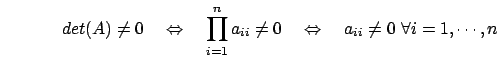 perché se sappiamo già che
questa sarà diagonale ci basterà memorizzare gli elementi non
nulli (quelli diagonali) in un vettore.
perché se sappiamo già che
questa sarà diagonale ci basterà memorizzare gli elementi non
nulli (quelli diagonali) in un vettore.